
Working with a Note Object on a Schematic Sheet in Altium Designer
This document is no longer available beyond version 21. Information can now be found here: Text Strings, Text Frames, and Notes for version 24
Parent page: Schematic Objects
 A placed Note
A placed Note
Summary
A note is a non-electrical drawing primitive. It is used to add informational or instructional text to a specific area within a schematic similar to that of commenting a program's source code. The note is a resizable rectangular area that can contain multiple lines of text and can automatically wrap and clip text to keep it within the bounds of the note.
Availability
Notes are available for placement in the Schematic Editor only in the following ways:
- Choose Place » Note from the main menus.
- Click the Note button (
 ) in the graphic objects drop-down on the Active Bar located at the top of the design space. (Click and hold an Active Bar button to access other related commands. Once a command has been used, it will become the top-most item on that section of the Active Bar.)
) in the graphic objects drop-down on the Active Bar located at the top of the design space. (Click and hold an Active Bar button to access other related commands. Once a command has been used, it will become the top-most item on that section of the Active Bar.) - Right-click in the design space then choose Place » Note from the context menu.
Placement
After launching the command, the cursor will change to a cross-hair and you will enter note placement mode. Placement is made by performing the following sequence of actions:
- Click or press Enter to anchor the first corner of the note.
- Move the cursor to adjust the size of the note then click or press Enter to complete placement.
- Continue placing further notes or right-click or press Esc to exit placement mode.
Additional actions that can be performed during placement while the note is still floating on the cursor and before its first corner is anchored are:
- Press the Tab key to pause the placement and access the Note mode of the Properties panel from where its properties can be changed on the fly. Click the design space pause button overlay (
 ) to resume placement.
) to resume placement. - Press the Spacebar to rotate the object counterclockwise or Shift+Spacebar for clockwise rotation. Rotation is in increments of 90°.
- Press the X or Y keys to mirror the note along the X-axis or Y-axis.
Graphical Editing
This method of editing allows you to select a placed note object directly in the design space and change its size, shape or location graphically.
A note can be displayed in either expanded (full frame) or collapsed (small triangle) modes. Toggle the display mode by clicking on the top left corner of a placed note.
 Click the triangle in the top-left corner to collapse a note.
Click the triangle in the top-left corner to collapse a note.
When a fully expanded note object is selected, the following editing handles are available:
.") A selected Note (fully expanded).
A selected Note (fully expanded).
- Click and drag A to resize the note in the vertical and horizontal directions simultaneously.
- Click and drag B to resize the note in the vertical and horizontal directions separately.
- Click anywhere on the note away from editing handles then drag to reposition it. While dragging, the note can be rotated (Spacebar/Shift+Spacebar) or mirrored (X or Y keys to mirror along the X-axis or Y-axis).
When a note is fully expanded, the textual content of that note can be edited in-place by:
- Single-clicking the note to select it.
- Single-clicking again (or pressing Enter) to enter the in-place editing mode. Sufficient time between each click should be given to ensure the software does not interpret the two single-clicks as one double-click (which would open the Properties panel).
- To finish editing in-place text, either click away from the note or press the green tick button (
 ). If you decide the change made is not needed, press the red cross button (
). If you decide the change made is not needed, press the red cross button ( ) to discard the change.
) to discard the change.
 Examples of in-place editing, with word wrapping enabled (top)
Examples of in-place editing, with word wrapping enabled (top)
and disabled (bottom).
The size and shape of a note cannot be changed graphically when it is in collapsed mode; only its location/orientation can be changed. As such, editing handles are not available when a collapsed note object is selected.
") A selected Note (collapsed)
A selected Note (collapsed)
Click anywhere inside the dashed box and drag to reposition the note as required. The note can be rotated or mirrored while dragging.
When a note is in collapsed mode, hover the cursor over it to access a pop-up containing the name of the note's author and the actual text content of the note.
 Hover over a collapsed note to display information.
Hover over a collapsed note to display information.
Non-Graphical Editing
The following methods of non-graphical editing are available.
Editing via the Note Dialog or Properties Panel
Properties page: Note Properties
This method of editing uses the associated Note dialog and the Properties panel mode to modify the properties of a note object.
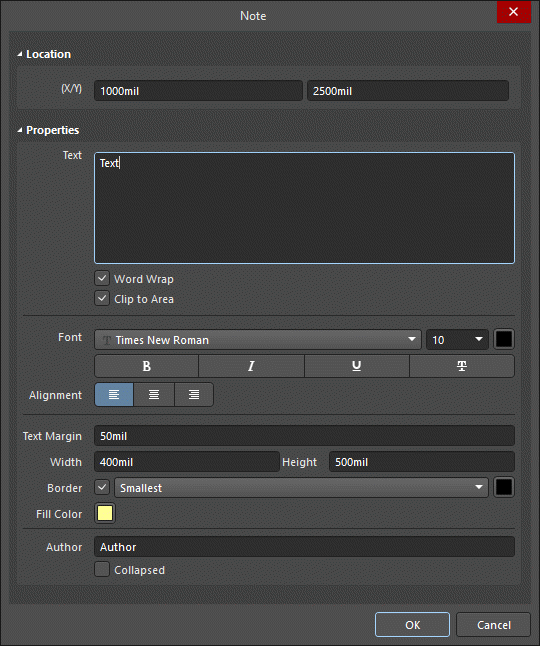
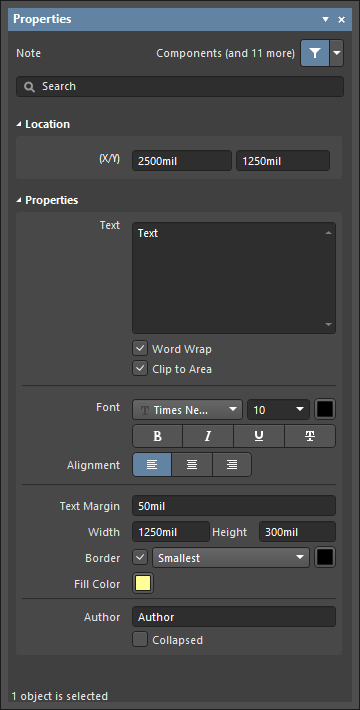 The Note dialog, on the left, and the Note mode of the Properties panel on the right
The Note dialog, on the left, and the Note mode of the Properties panel on the right
After placement, the Note dialog can be accessed by:
- Double-clicking on the placed Note object.
- Placing the cursor over the Note object, right-clicking then choosing Properties from the context menu.
During placement, the Note mode of the Properties panel can be accessed by pressing the Tab key. Once the Note is placed, all options appear.
After placement, the Note mode of the Properties panel can be accessed in one of the following ways:
- If the Properties panel is already active, by selecting the Note object.
- After selecting the Note object, select the Properties panel from the Panels button at the bottom right of the design space or select View » Panels » Properties from the main menu.
Editing Multiple Objects
The Properties panel supports multiple object editing, where the property settings that are identical in all currently selected objects may be modified. When multiples of the same object type are selected manually, via the Find Similar Objects dialog or through a SCH Filter or SCH List panel, a Properties panel field entry that is not shown as an asterisk (*) may be edited for all selected objects.
Wrapping and Clipping Text
In addition to providing a Word Wrap option, the Properties panel provides a Clip to Area option. This option comes into play if word wrapping is disabled. With this option enabled, text will be kept within the bounds of the note's frame. When disabled, text will spill out of the frame onto the schematic sheet.
 Example of word wrapping and the effect of clipping
Example of word wrapping and the effect of clipping
Specifying Text Margins
Specify a single value to apply equally to Left, Top, Right, and Bottom margins for the current note using the Text Margin in the Properties panel.
.") Example note with a Text Margin setting of 20 (Default DXP Units, equivalent to 200mil).
Example note with a Text Margin setting of 20 (Default DXP Units, equivalent to 200mil).
When editing text in place directly within the note's frame, the defined margins are not present. They will be reapplied after editing is complete and the text changes are applied.
 Margins are not shown while graphically modifying the text in place.
Margins are not shown while graphically modifying the text in place.
Editing via a List Panel
Panel pages: SCH List, SCH Filter
A List panel allows you to display design objects from one or more documents in tabular format, enabling quick inspection and modification of object attributes. Used in conjunction with appropriate filtering - by using the SCH Filter panel or the Find Similar Objects dialog - it enables the display of just those objects falling under the scope of the active filter – allowing you to target and edit multiple design objects with greater accuracy and efficiency.
Note
While notes can be rotated or mirrored along the X or Y axis, this has no effect on the orientation of the text within.