
ジャンパー部品の作成
Jumpers, also referred to as wire links, allow you to replace routing with a Jumper component, which is often an essential ingredient to successfully designing a single-sided board.
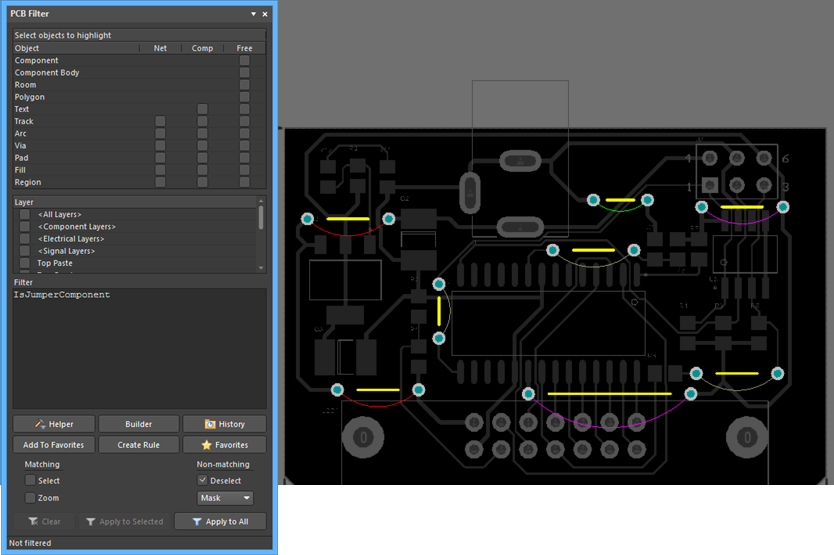
Early printed circuit boards were all single sided. To successfully implement all of the connections, jumpers or wire links were often used to create another layer of connectivity, which could pass across the printed routing. The image below shows an example of Jumpers being used to implement the routing on one side of the board.
Note the representation of a Jumper, with a curved connection line between the two pads. In the image, the jumper connection lines are shown in different colors because they inherit the color assigned to the net.
What Defines a Jumper?
To act as a jumper, you need:
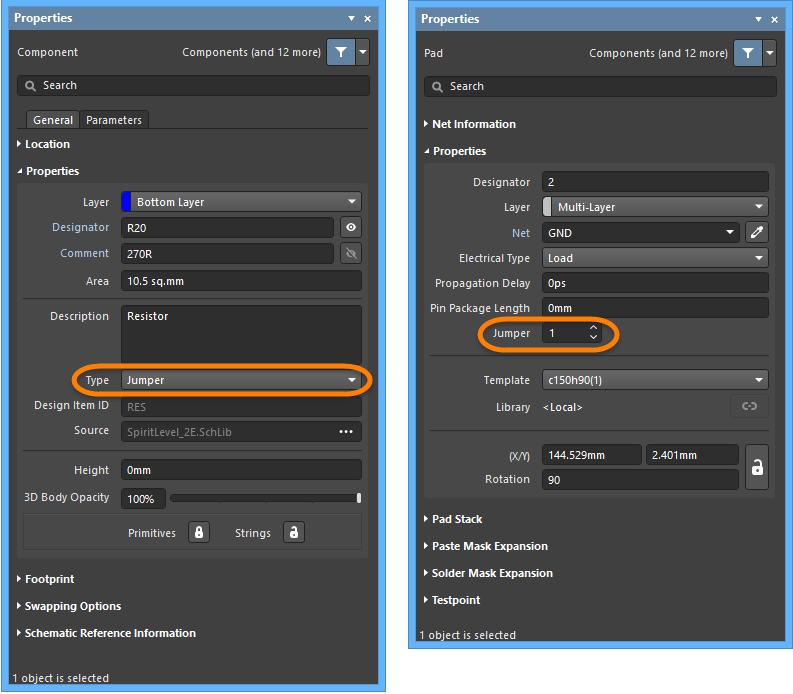
- The component Type set to Jumper.
- The Jumper value set to the same, non-zero value for pads in the Jumper component.
How Jumpers are Used
After placing a Jumper in the workspace you will need to set the Net attribute of one of the pads manually in the Properties panel since there is no automatic net inheritance. Note that if the component is defined as a Jumper, then the other pad will automatically inherit the same Net name.
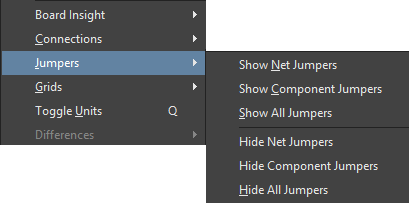
Controlling the Display of Jumpers
The View menu includes a Jumpers sub-menu that allows control over the display of Jumper components.
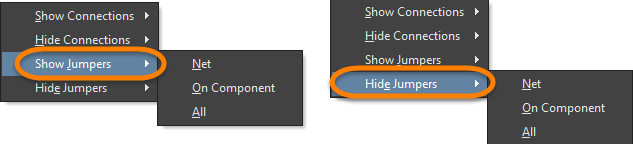
There are also Jumper sub-menus in the Netlist popup menu (N shortcut).
The query keyword IsJumperComponent is available for filtering and rule definition.
Jumpers and the Bill of Materials
Jumpers are typically pieces of tinned copper wire that are bent to the correct length, meaning they need to be in the BOM. To support this, Jumpers also can be included on the schematic so that they are included in the Bill of Materials. The Synchronizer and the Report engine have the following behavior for synchronizing Jumpers:
- The component itself is synchronized.
- Net properties of Jumper pins are not synchronized.
- The Jumper is included in the BOM.
Suggested Workflow for Working with Jumpers
The following description is one approach to working with Jumper components. This workflow starts at the schematic, but you can also start by placing the Jumper footprints directly onto the PCB. The main reason for starting on the schematic is that when the design is transferred to the PCB workspace, the footprints will have the correct component Type of Jumper. If you place them directly from the PCB library into the PCB workspace, the component Type will default to Standard, so you will need to manually set it.
Create the Jumper Footprints in the PCB Library
Create a footprint for each length jumper that will be used. Typically jumpers are designed in pre-defined lengths, for example, in increments of 0.1 inch (100 mils).
As mentioned above, there are two conditions that make a Jumper a Jumper:
- Both pads in the Jumper must have their Jumper value set to the same, non-zero value in the Properties panel. Note that it does not matter if the pads in all Jumper footprints used on a board design have the same Jumper value.
- The Jumper Component must have its Type set to
Jumperin the Properties panel. Note that this can only be set once the footprint has been placed into the PCB workspace; it cannot be set in the PCB Library editor.
The image below shows a typical Jumper in the PCB Library editor. Both pads have the Jumper value of 1.

Create the Schematic Jumper Component
On the schematic side, you can either:
- Create a single Jumper component, then add to it all of the different length Jumper footprints that you need.
- Create an individual Jumper component for each different length Jumper footprint that will be used.
Once the symbol has been created:
- Set the default Designator.
- Set the Component Type to
Jumper. - Add the various Jumper footprints to the Models list.
- Define the other component properties you need, such as the Description and any required component Parameters on the Parameters tab.
Placing Jumpers onto the Schematic
Once the Jumper has been designed, you can place a number of them onto the schematic. At this stage, you probably do not know how many you will need, however, extras can easily be deleted. Keep in mind they are on the schematic to ensure they go into the BOM; they do not need to be wired into the circuit at each location that they end up being used. For that reason, it makes sense to place them all on the same schematic sheet, perhaps with other BOM-only hardware, such as screws.

When a Design » Update PCB Document command is performed, all of the jumpers will be placed into the PCB workspace using the default footprint to the right of the board shape.
Position and Routing the Jumpers on the PCB
The image below shows the PCB, almost completely routed. Note the remaining connection lines showing where the routes are not complete. There are also a number of un-placed Jumper components to the right of the board.
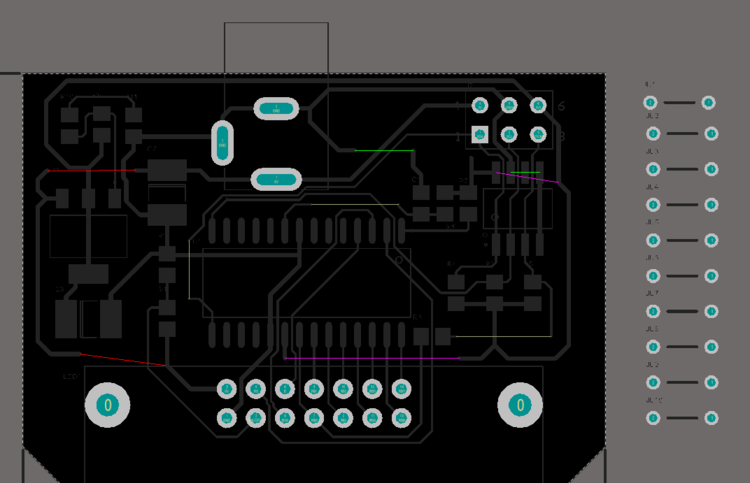
The routing for each of these connections cannot be completed because there is no route path available on this single-sided design. To complete them, the Jumper components will be used.
To complete a connection with a Jumper:
- Drag a jumper component into position on the board. If it is not long enough, either press Tab while moving the Jumper or double-click once it is placed to open the Component mode of the Properties panel.
- In the Footprint region of the Properties panel, enter the Footprint Name, or click the
 to open the Browse Libraries dialog to select a footprint.
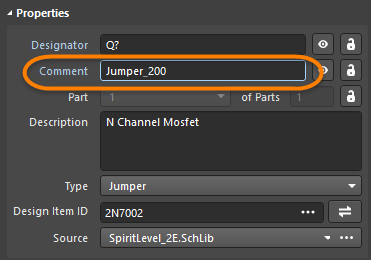
to open the Browse Libraries dialog to select a footprint. - To make it easier to include the Jumper in the BOM, enter a suitable identifying string in the Comment field. In the image below, the footprint name has been copied and pasted into the Comment field since it describes how long the jumper is.
- Position the Jumper in the required location.
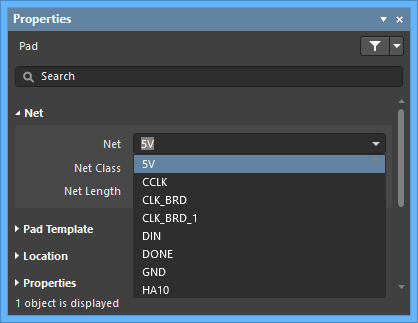
- Double-click to edit one of the pads then select the required net name from the Net drop-down list in the Properties region of the Properties panel. The other pad in the Jumper will automatically be assigned the same net name.
- Once all Jumpers have been placed, delete any unused Jumpers from the board.
- Run the Design » Update Schematics command to push the footprint and comment changes back to the schematic.
- The last step is to remove any unused Jumper components from the schematic. These can be identified by switching to one of the schematic sheets and running the Design » Update PCB Document command. The Engineering Change Order dialog will open and list any extra components on the schematic; note their designators then close the ECO dialog and delete those excess Jumpers from the schematic.