
基于 Microsoft Word 模板的规范导出(11 月更新)
利用 Requirements & Systems Portal 的 Python 和 Rest API(允许完全访问所有数据),并结合 Microsoft Word 的合并字段功能,可以一键将需求规格导出为 Word 文档。通过该功能,您可以选择在文档中包含哪些需求字段以及如何放置这些字段。
合并字段和模板
合并字段通过其名称作为数据字段的参考。当模板文档与数据源中的值进行邮件合并时,数据字段信息将取代合并字段。
通过创建具有不同合并字段的模板文档,可以根据它们快速生成相同类型的输出文档(规格或其他)。
创建新的合并字段
-
打开要编辑的文档,转到
Insert -
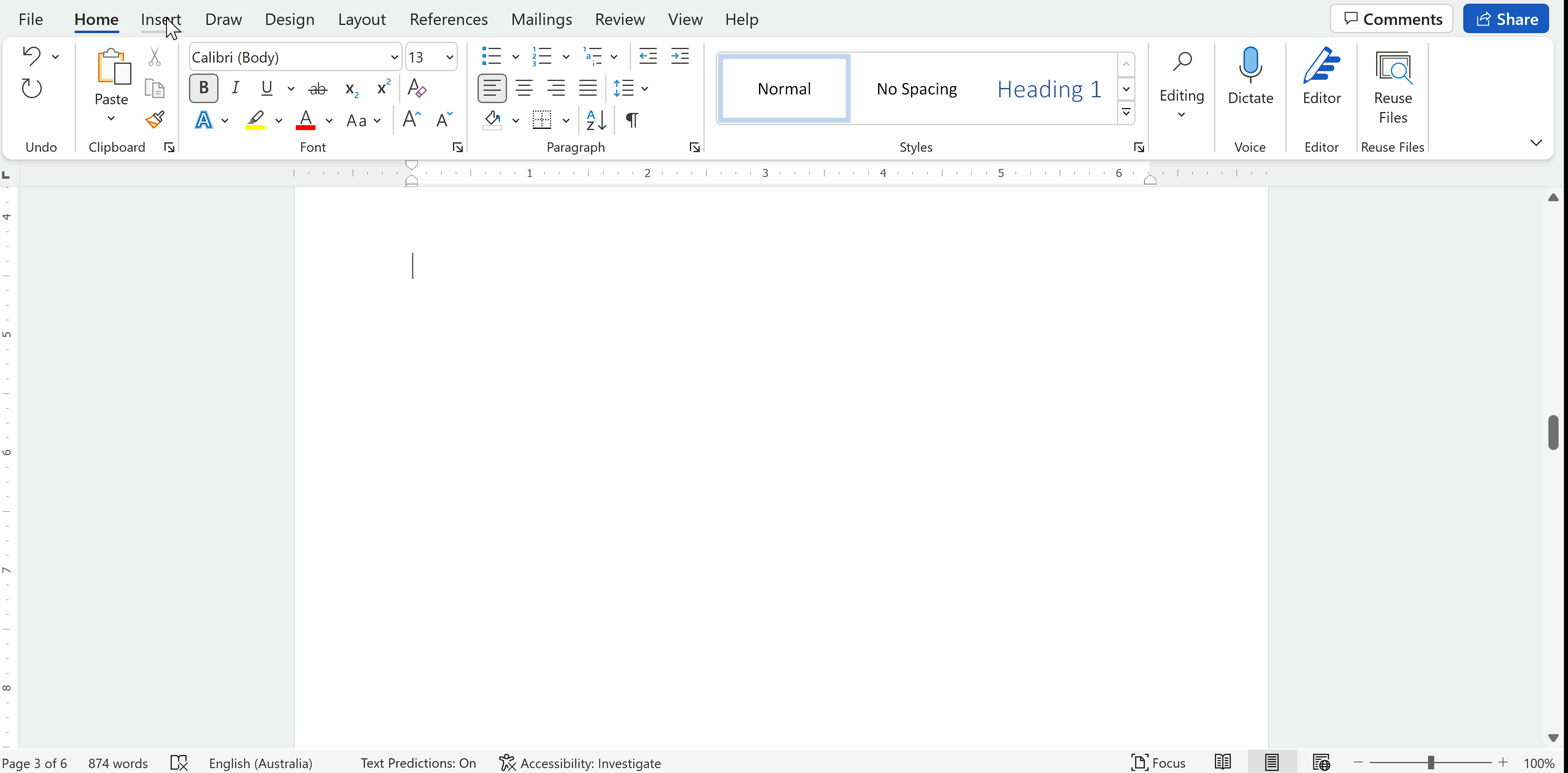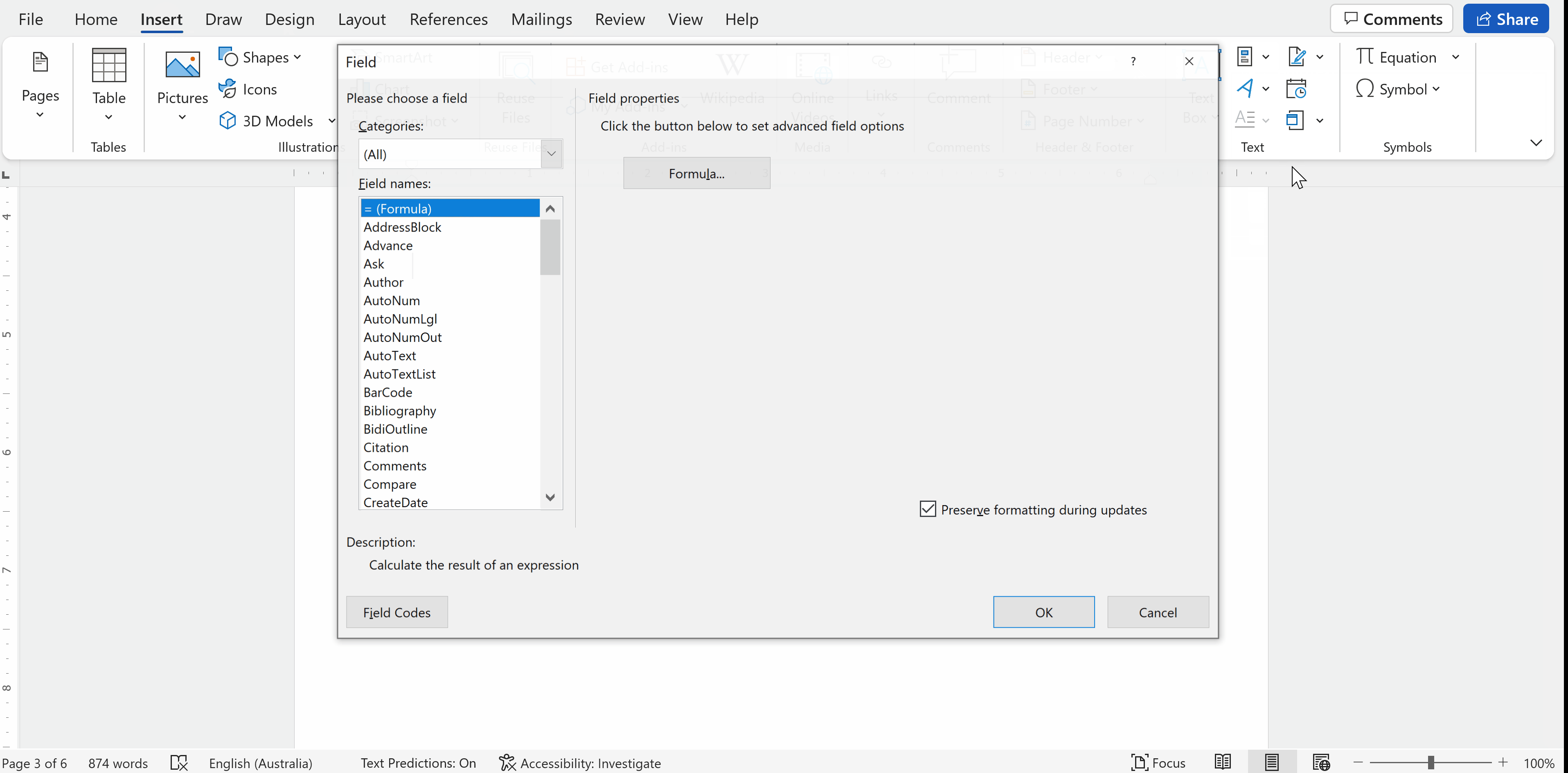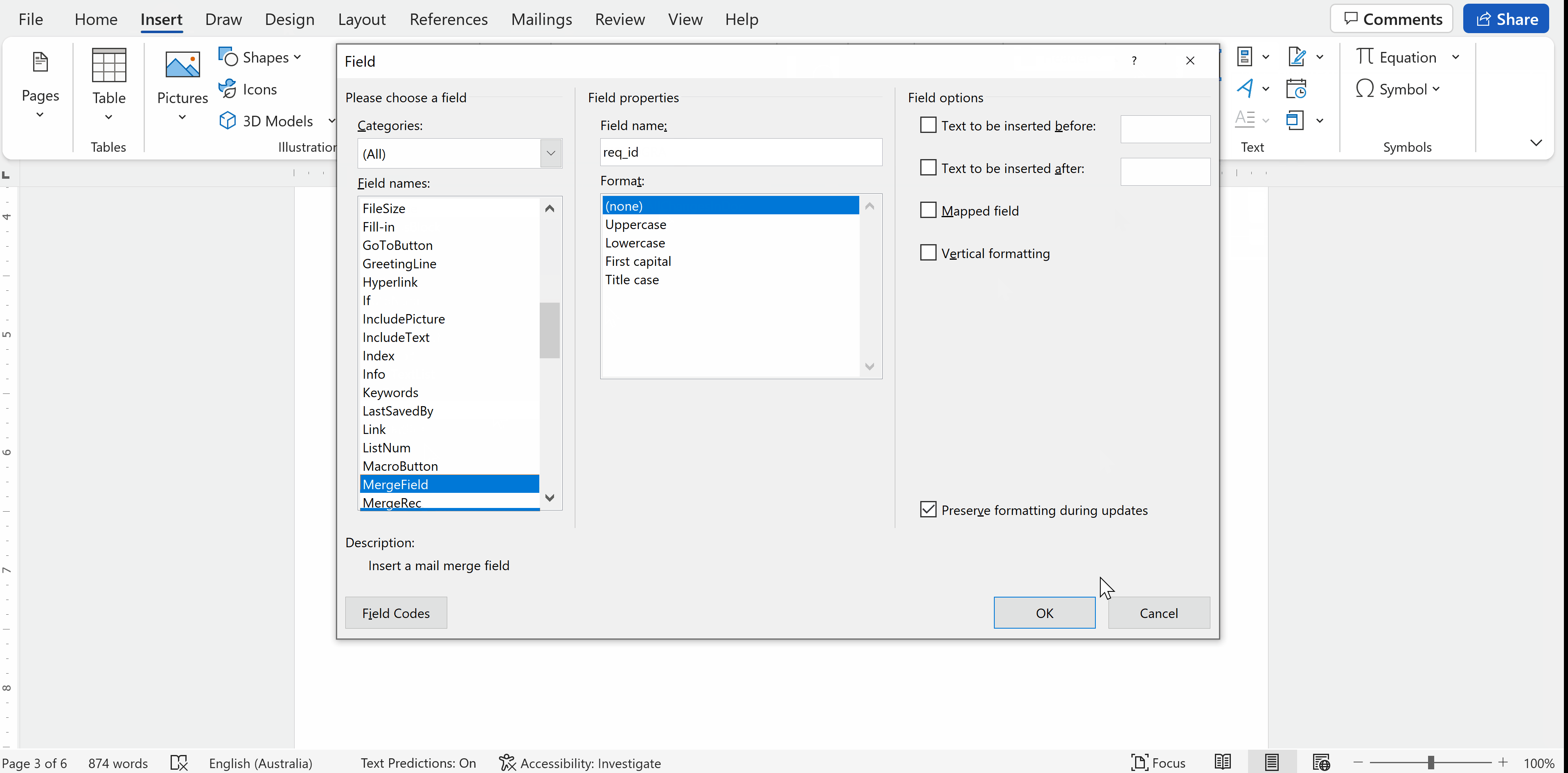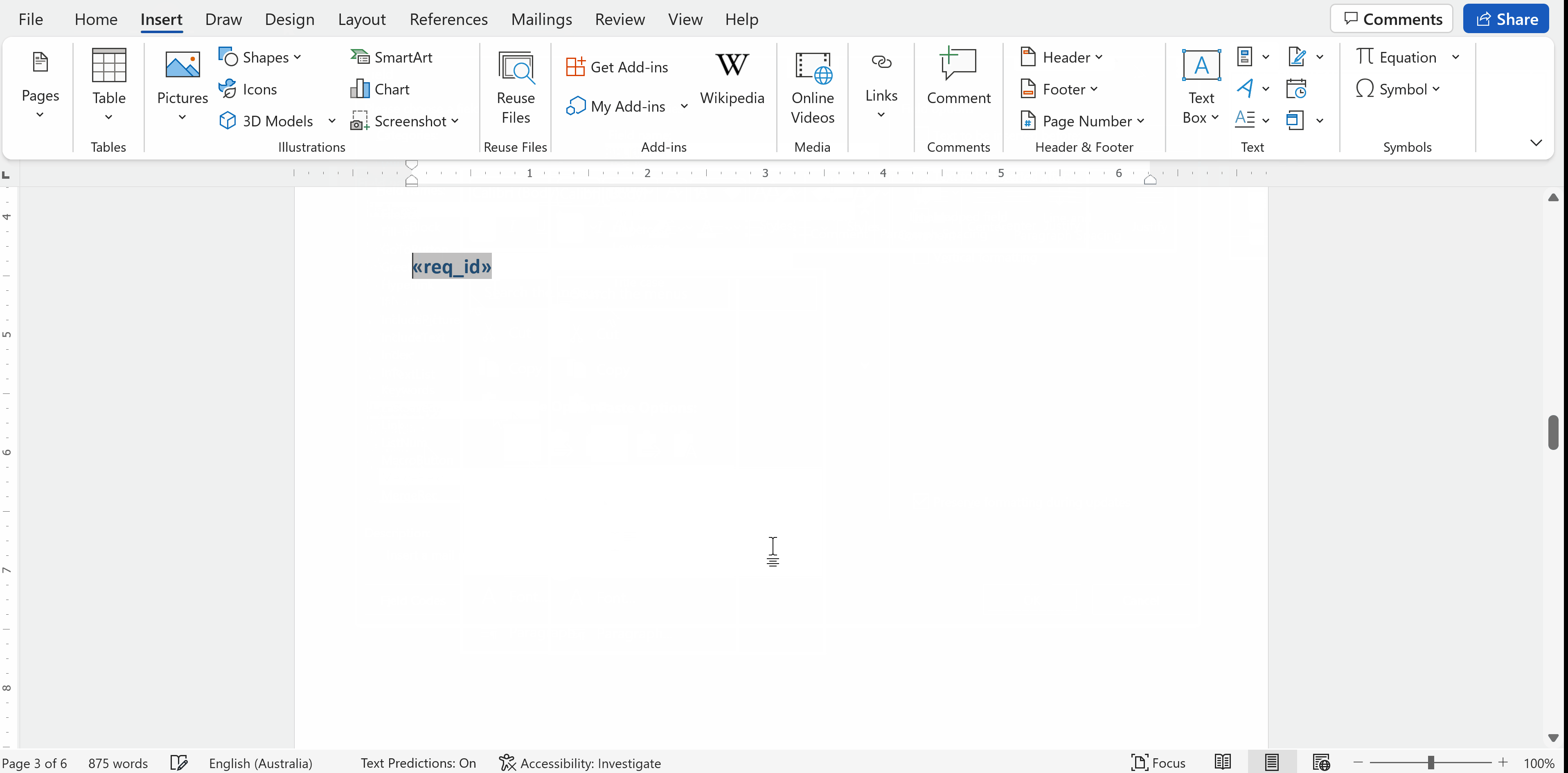
打开
Quick PartdFieldField -
在字段对话框菜单中选择
Merge FieldField nameOK
提示:根据要替换的数据命名字段,以便于跟踪 -
合并字段将插入 Word 文件。单击该对象后,它将以灰色高亮显示。
已经定义了相应 Python 函数的合并字段有
"req_id" - 需求标识符
"req_title" - 需求标题
"req_text" - 需求文本
"req_state" - 需求状态
"req_type" - 需求类型
"req_rationale" - 与需求相关的理由
"images" - 附加到需求的图像
"specification_name" - 包含该要求的规范
"section_name" - 包含该要求的章节
"req_compliance" - 符合要求的声明
"req_comp_comment" - 符合要求的注释
"req_owner" - 要求的所有者
"req_applicability" - 要求的适用性
"要求 "验证方法
req_ver_m_text" - 要求 "验证方法注释
req_ver_closeout_ref" - "需求 "验证方法关闭引用
"req_ver_status" - 需求'验证方法状态创建模板(用于模板复制)
合并字段的组合可用于创建用于生成规范文档的模板文件。
下图是一个模板示例,其中一些字段写在 "纯文本 "上,另一些则作为表格的一部分。该示例是下一节将介绍的 Python 脚本的基础示例。
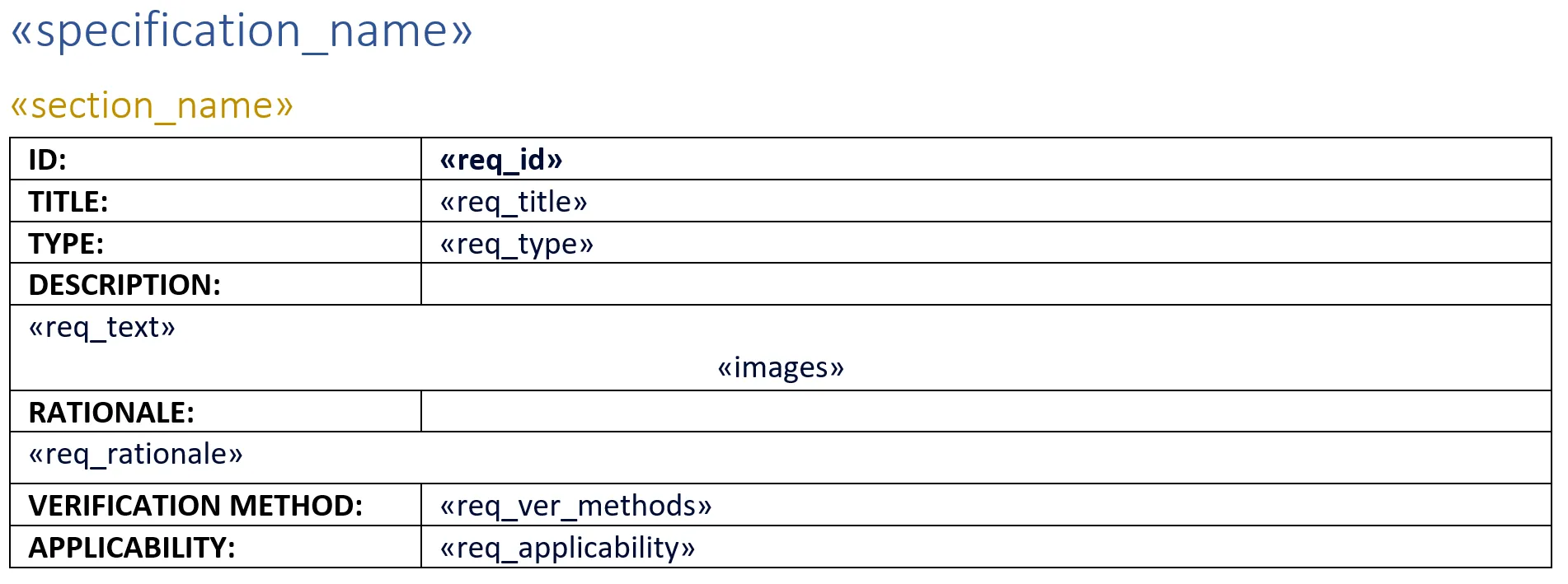
该模板的输出结果与下图类似
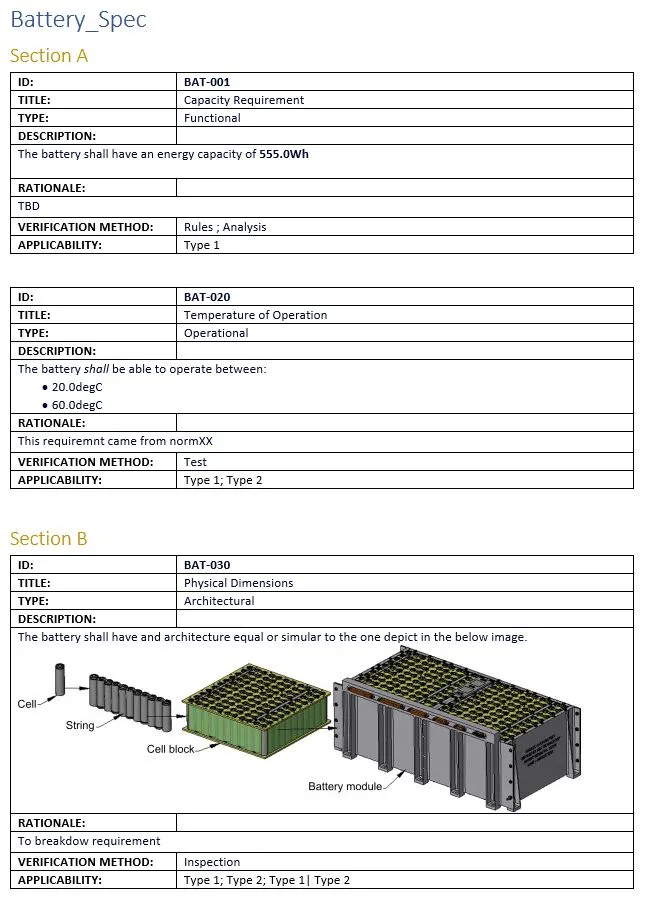
填充模板的 Python 脚本
Python 脚本用于根据合并字段填充的模板生成文档,主要使用以下软件包:
-
valispace -
docx-mailmerge2 -
python-docx -
htmldocx
代码分为 3 类函数:
-
Master functionsmaincreate_specification_document -
Requirement data extract functions -
Document "Format" functions
在下面的章节中,我们将简要介绍这些功能。
主函数 - 主
该函数允许用户插入域名、用户名和密码、项目标识符(生成规范的依据)以及模板文件的路径。
然后,它将使用这些信息来
-
使用 Python API 登录需求与系统门户;
-
下载项目通用数据,如规格、图像、需求类型等;
-
调用函数
create_specification_document
主函数 - 创建规格文件
该函数将通过在模板上的合并字段中填入相应的需求数据来创建生成规格文件。
最初,需要收集所选规范的所有需求:
all_specification_requirements = get_map(api, f "requirements/complete/?project="+str(DEFAULT_VALUES["project"])+"&clean_html=text&clean_text=comment", "id", None, filter_specification)
如果 len(all_specification_requirements) 1:
print("No requirements for Specification -> "+ specification_data['name'])
返回然后,它将按章节组织需求数据,从没有任何章节的需求开始。
为了获取这些非章节需求,支持函数 get_requirements_without_section
#首先,我们将在文档中添加无章节需求
no_section_requirements = get_requirements_without_section(all_specification_requirements)现在,所有非章节需求都已收集完毕,是时候准备数据来填充合并字段了。这些数据将借助 Requirement data extract functions
template_data.append({
"specification_name" : CURRENT_SPECIFICATION["name"] if counter == 1 else ""、
"section_name" : ""、
"req_id" : reqdata['标识符']、
"req_title":reqdata['title']、
"req_text":reqdata['标识符']+"_docx"、
"req_type" : req_type、
"req_rationale":reqdata['comment']、
"req_ver_methods" : req_vms、
"req_applicability": req_applicability、
"images" : "Images_Placeholder_"+str(requirement) if requirement_with_images == True else "No_Images" (无图像)
})对于大多数合并字段,数据是直接映射的,但对于 imagesreq_text
-
对于
images -
对于
req_textdocx_list[reqdata['identifier']+"_docx"] = new_parser.parse_html_string(reqdata['text'])
对于有章节的需求,将重复同样的过程,一旦完成,数据将合并到模板字段中,并存储为一个新文件:
document.merge_templates(template_data, separator='continuous_section')
document.write(OUTPUT_FILE)最后,我们将使用 Document "Format" functions
document2 = Document(OUTPUT_FILE)
remove_all_but_last_section(document2)
remove_all_empty_headings(document2)
put_html_text(document2, docx_list)
put_images(document2, all_project_images)
keep_tables_on_one_page(document2)
document2.save(OUTPUT_FILE)
print ("Specification document created -> "+ specification_data['name'])需求数据提取函数
从需求中提取数据的函数如下:
-
get_requirements_without_section -
get_specification_sections -
get_section_requirements -
get_requirement_images -
get_requirement_type -
get_requirement_state -
get_requirement_owner -
get_requirement_applicability -
get_requirement_verification_methods -
get_requirement_verification_methods_newline -
get_requirement_verification_methods_comments -
get_requirement_verification_status -
get_requirement_verification_closeout_refs -
get_requirement_attachments_references -
get_requirement_custom_field
文档 "格式 "函数
用于格式化最终文档的函数如下:
-
keep_tables_on_one_page -
remove_all_empty_headings -
remove_all_but_last_section -
put_images -
clone_run_props -
put_html_text
下载最新的通用模板、Python 脚本或可执行文件
通用规范创建 Nov2023.py 通用规范模板.docx 要求.txt
运行脚本前需要编辑的内容:
从创建脚本到生成文档,运行此代码的完整过程已在下面的视频中说明(无音频)。
如果您需要有关更改模板、提取其他信息以填充模板的指导,或与此功能相关的任何问题,请随时通过我们的Altium 支持页面向我们发送您的问题/请求。
 AI 翻译
AI 翻译