
Export des spécifications basé sur un modèle Microsoft Word (mise à jour de novembre)
En tirant parti de l’API Python & REST de Requirements & Systems Portal, qui permet un accès complet à toutes les données, et en la combinant avec la fonctionnalité de champs de fusion de Microsoft Word, il existe une fonctionnalité en un clic pour exporter vos spécifications d’exigences dans un document Word. Cette fonctionnalité vous donne la possibilité de choisir quels champs d’exigence vous souhaitez inclure dans votre document et comment les positionner.
Champs de fusion et modèles
Les champs de fusion sont utilisés comme référence à un champ de données par leur nom. Lorsqu’un document modèle est fusionné avec les valeurs d’une source de données, les informations du champ de données remplacent le champ de fusion.
En créant un document modèle avec différents champs de fusion, il est possible de générer rapidement le même type de document de sortie (spécifications ou autres) à partir de ceux-ci.
Créer un nouveau champ de fusion
-
Ouvrez le document que vous souhaitez modifier et accédez à l’onglet
Insert. -
Ouvrez le menu
Quick Partdet sélectionnezField. La boîte de dialogueFields’ouvrira. -
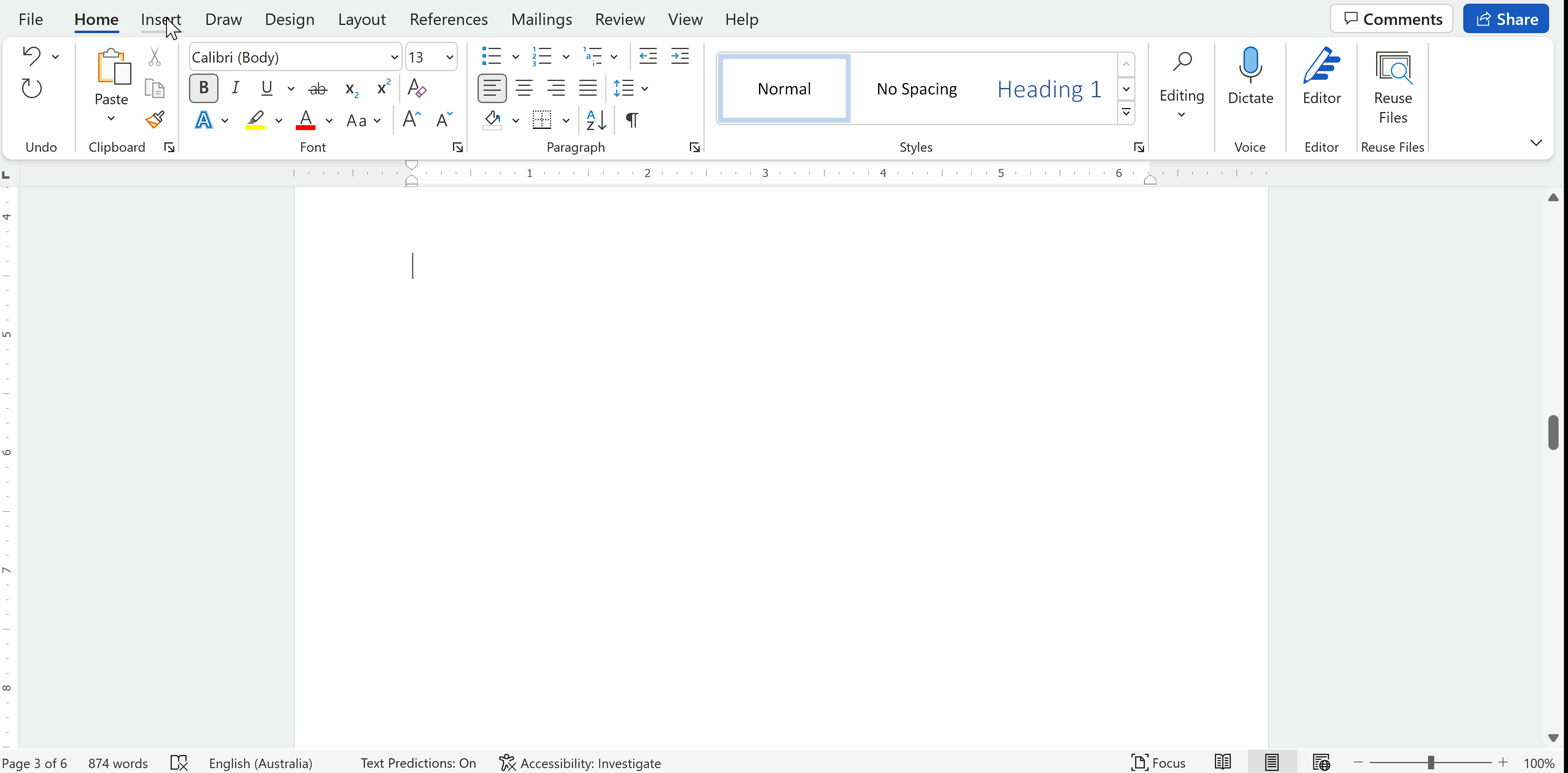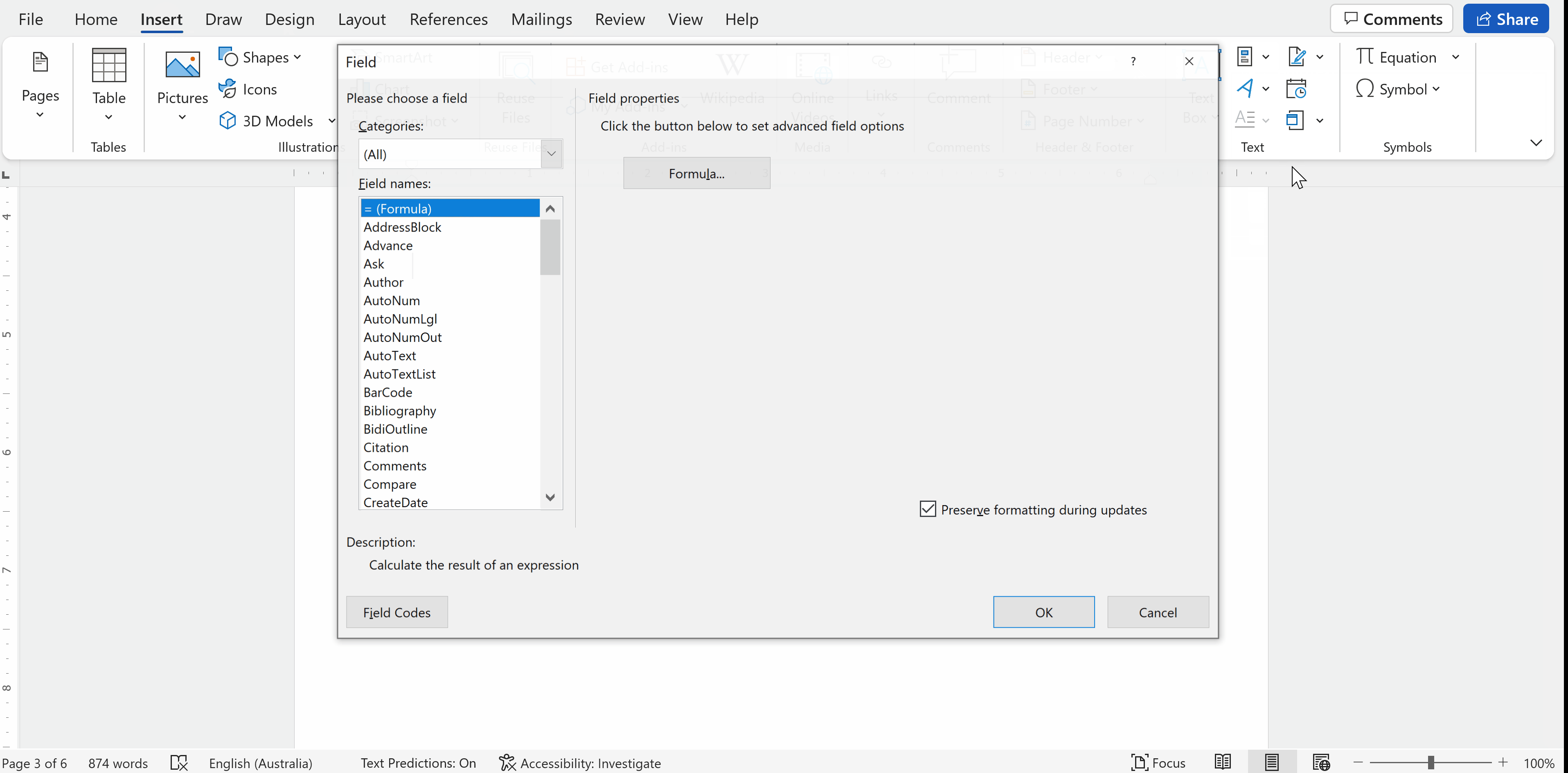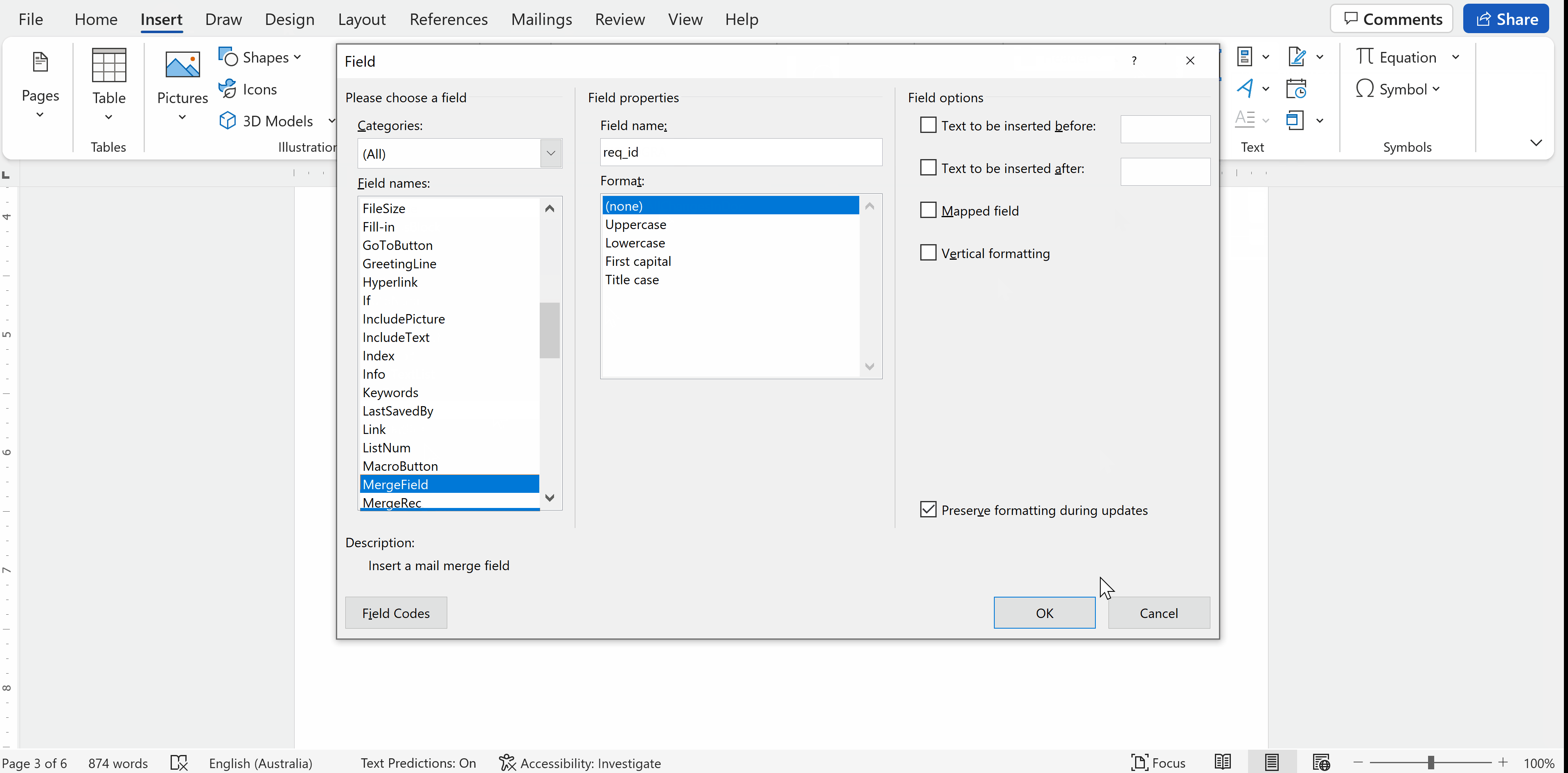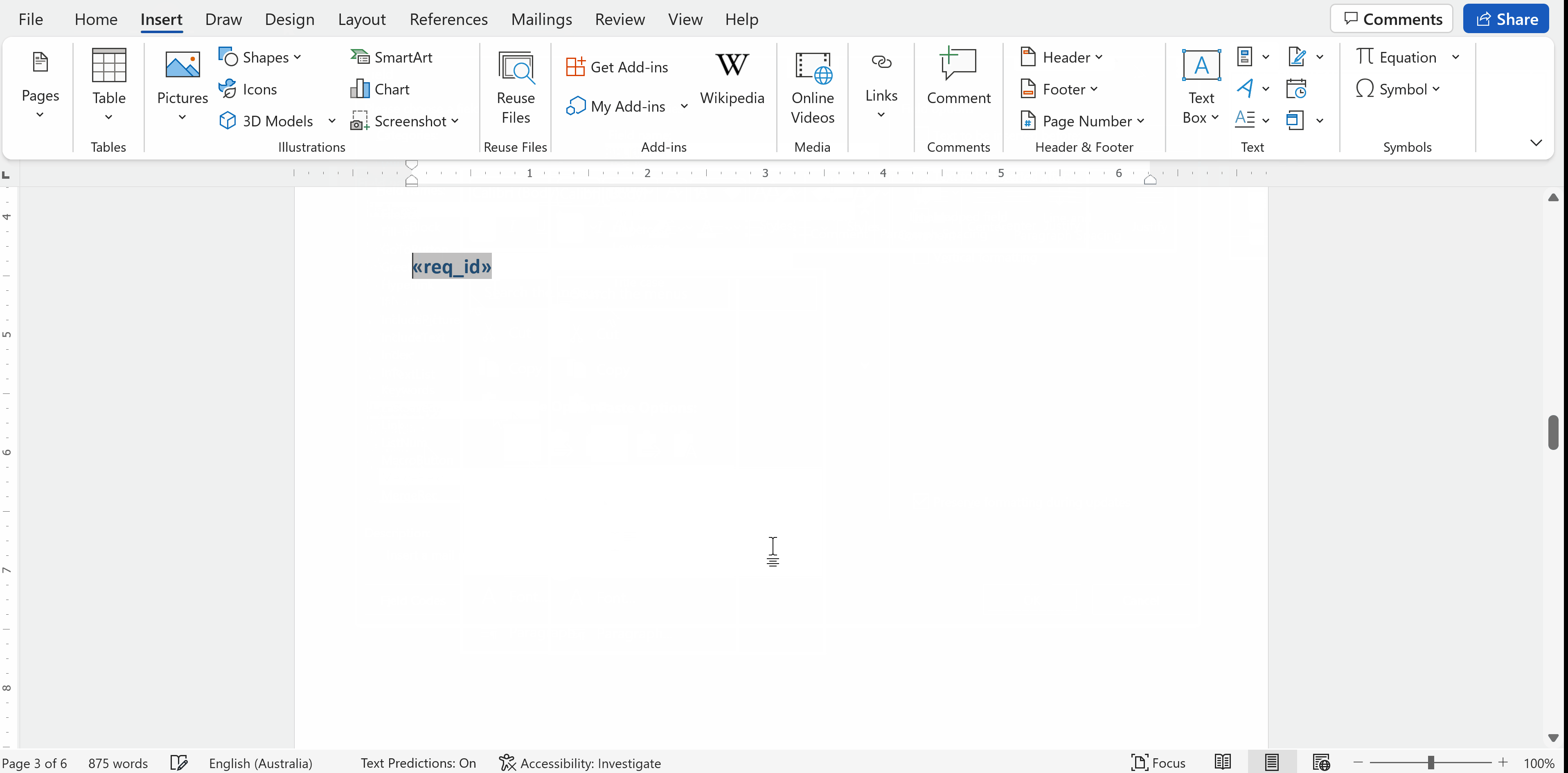
Dans le menu de la boîte de dialogue des champs, choisissez
Merge Fielddans la liste de gauche. Saisissez le nom du champ de fusion dans la zone de texteField nameà droite, puis cliquez surOK.
Astuce : nommez le champ en fonction des données par lesquelles il doit être remplacé afin de le repérer plus facilement -
Le champ de fusion est inséré dans le fichier Word. L’objet doit être surligné en gris si vous cliquez dessus.
Les champs de fusion pour lesquels des fonctions Python correspondantes sont déjà définies sont :
«req_id» - Identifiant de l’exigence «req_title» - Titre de l’exigence «req_text» - Texte de l’exigence «req_state» - État de l’exigence «req_type» - Type d’exigence «req_rationale» – Justification associée à une exigence «images» – Images jointes à une exigence «specification_name» - Spécification contenant l’exigence «section_name» - Section contenant l’exigence «req_compliance» - Déclaration(s) de conformité des exigences «req_comp_comment» - Commentaires de conformité des exigences «req_owner» - Propriétaire des exigences «req_applicability» - Applicabilité des exigences «req_ver_methods» - Méthodes de vérification des exigences «req_ver_m_text» - Commentaires sur les méthodes de vérification des exigences «req_ver_closeout_ref» - Références de clôture des méthodes de vérification des exigences «req_ver_status» - Statut des méthodes de vérification des exigences
Création de modèles (pour la réplication de modèles)
Une combinaison de champs de fusion peut être utilisée pour créer les fichiers modèles qui serviront à générer les documents de spécification.
Un exemple de modèle est présenté ci-dessous, où certains champs sont écrits en « texte brut » et d’autres font partie d’un tableau. Cet exemple constitue la base des scripts Python qui seront décrits dans la section suivante.
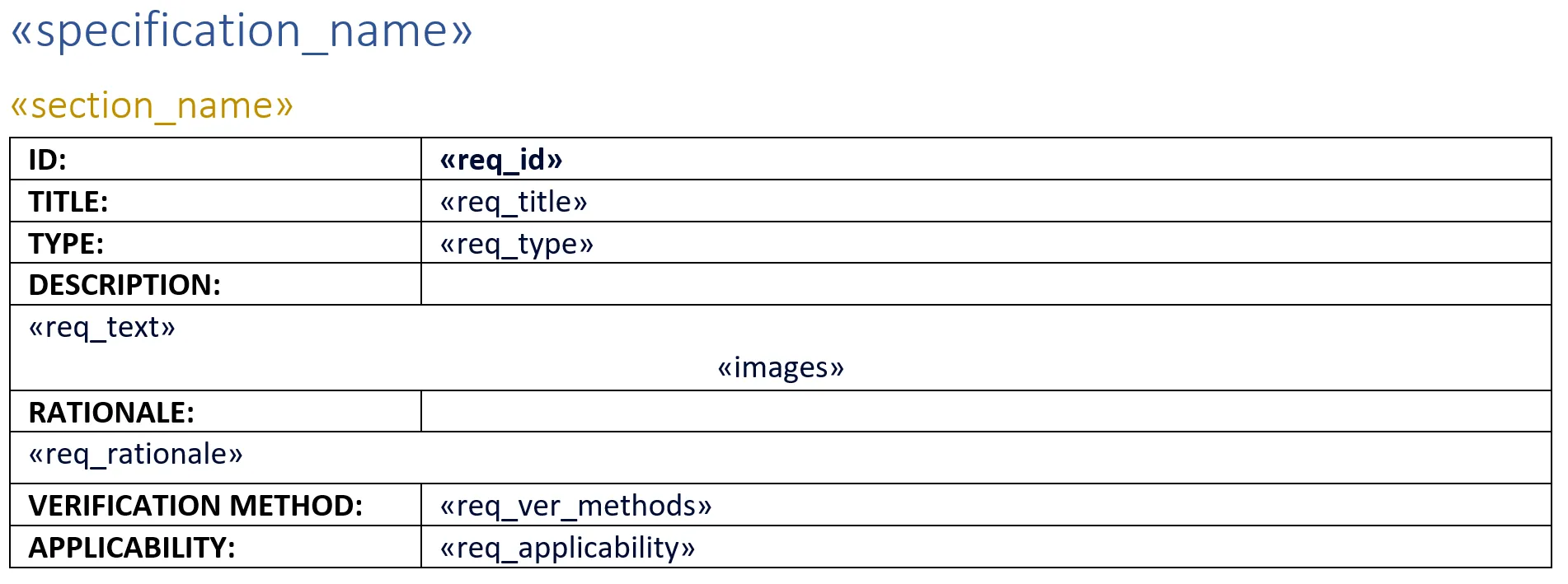
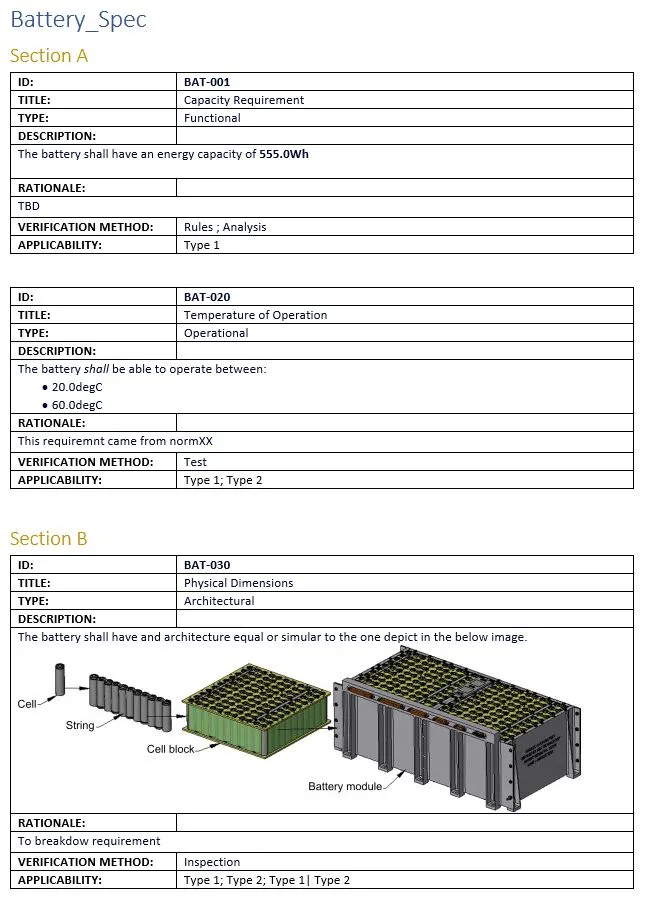
Le résultat produit par ce modèle ressemblerait à l’image ci-dessous
Script Python pour renseigner le modèle
Le script Python utilisé pour générer des documents à partir d’un modèle renseigné avec des champs de fusion repose sur l’utilisation des principaux packages suivants :
-
valispace- L’API Python de Requirements & Systems Portal vous permet d’accéder aux objets dans Requirements & Systems Portal et de les mettre à jour. -
docx-mailmerge2- Effectue une fusion de publipostage (remplace les champs de fusion par les données souhaitées) sur des fichiers Office Open XML (Docx) et peut être utilisé sur n’importe quel système sans avoir à installer Microsoft Office Word. -
python-docx- Bibliothèque Python pour créer et mettre à jour des fichiers Microsoft Word (.docx). -
htmldocx- Bibliothèque Python pour convertir du HTML en Docx. Utilisée pour conserver la mise en forme de Requirements & Systems Portal dans Word (gras, italique, puces…)
Le code est divisé en 3 types de fonctions :
-
Master functions- Composé des fonctionsmainetcreate_specification_documentqui contiennent la logique permettant d’exporter les exigences vers le document final en renseignant le modèle fourni -
Requirement data extract functions- Ce sont toutes les fonctions permettant d’extraire les données des exigences telles que le type d’exigence, l’état, les images… -
Document "Format" functions- Fonctions qui effectuent la mise en forme, comme la suppression des espaces blancs et le fait de s’assurer que les tableaux ne sont pas coupés dans le document final généré
Dans le sous-chapitre suivant, nous expliquons brièvement ces fonctions.
Fonctions maîtresses - Main
Cette fonction permet à l’utilisateur de saisir le nom de domaine, son nom d’utilisateur et son mot de passe, l’identifiant du projet à partir duquel générer les spécifications, ainsi que le chemin vers le fichier modèle
Elle utilisera ensuite ces informations pour :
-
Se connecter à Requirements & Systems Portal à l’aide de l’API Python ;
-
Télécharger les données génériques du projet telles que les spécifications, les images, les types d’exigence et autres ;
-
Appeler la fonction
create_specification_documentpour chaque spécification du projet sélectionné.
Fonctions maîtresses - Create_specification_document
Les fonctions créeront le fichier de spécifications en renseignant les champs de fusion du modèle avec les données d’exigence correspondantes.
Initialement, toutes les exigences de la spécification sélectionnée doivent être collectées :
all_specification_requirements = get_map(api, f"requirements/complete/?project="+str(DEFAULT_VALUES["project"])+"&clean_html=text&clean_text=comment", "id", None, filter_specification)
if len(all_specification_requirements) <1:
print("No requirements for Specification -> "+ specification_data['name'])
return
Ensuite, les données des exigences seront organisées par section, en commençant par les exigences sans section.
Pour obtenir ces exigences sans section, la fonction d’assistance get_requirements_without_section est utilisée afin de filtrer toutes les exigences de la spécification qui n’ont pas de groupe (la manière dont les sections sont stockées dans le backend de Requirements & Systems Portal) et de les trier par ordre alphabétique.
#1st we will add requirements without section to the document
no_section_requirements = get_requirements_without_section(all_specification_requirements)
Maintenant que toutes les exigences sans section ont été rassemblées, il est temps de préparer les données qui renseigneront les champs de fusion. Ces données sont récupérées à l’aide de Requirement data extract functions et seront stockées dans la liste Python comme indiqué dans le code ci-dessous.
template_data.append({
"specification_name" : CURRENT_SPECIFICATION["name"] if counter == 1 else "",
"section_name" : "",
"req_id" : reqdata['identifier'],
"req_title" : reqdata['title'],
"req_text" : reqdata['identifier']+"_docx",
"req_type" : req_type,
"req_rationale" : reqdata['comment'],
"req_ver_methods" : req_vms,
"req_applicability" : req_applicability,
"images" : "Images_Placeholder_"+str(requirement) if requirement_with_images == True else "No_Images"
})
Pour la majorité des champs fusionnés, les données sont mappées directement, mais pour imagesetreq_text, les données seront fusionnées à une étape ultérieure :
-
Pour
images, un indicateur signalant si l’exigence comporte des images ou non est stocké comme donnée -
Pour
req_text, un espace réservé est stocké comme donnée. Cet espace réservé sera également utilisé comme clé dans une liste contenant le résultat de l’analyse du texte de l’exigence depuis le HTML vers Word, comme indiqué dans le code ci-dessousdocx_list[reqdata['identifier']+"_docx"] = new_parser.parse_html_string(reqdata['text'])
Le même processus sera répété pour les exigences qui ont des sections et, une fois cela fait, les données seront fusionnées dans les champs du modèle et enregistrées dans un nouveau fichier :
document.merge_templates(template_data, separator='continuous_section') document.write(OUTPUT_FILE)
Enfin, nous utiliserons le Document "Format" functions pour finaliser le document en supprimant les sections vides et les en-têtes vides, en gardant les tableaux sur une seule page, et en insérant dans le document le texte formaté des exigences ainsi que leurs images
document2 = Document(OUTPUT_FILE)
remove_all_but_last_section(document2)
remove_all_empty_headings(document2)
put_html_text(document2, docx_list)
put_images(document2, all_project_images)
keep_tables_on_one_page(document2)
document2.save(OUTPUT_FILE)
print ("Specification document created -> "+ specification_data['name'])
Fonctions d’extraction des données d’exigence
Les fonctions disponibles pour extraire les données des exigences sont les suivantes :
-
get_requirements_without_section- Renvoie une liste triée de toutes les exigences sans section -
get_specification_sections- Renvoie une liste de toutes les sections de la spécification donnée -
get_section_requirements- Renvoie une liste triée de toutes les exigences de la section donnée -
get_requirement_images- Renvoie un tableau de toutes les images des exigences -
get_requirement_type- Renvoie le nom du type d’exigence -
get_requirement_state- Renvoie le nom de l’état de l’exigence -
get_requirement_owner- Renvoie les groupes d’utilisateurs ainsi que le prénom et le nom du propriétaire de l’exigence -
get_requirement_applicability- Renvoie une liste de tous les types de blocs applicables à l’exigence, séparés par un « ; » -
get_requirement_verification_methods- Renvoie le nom de toutes les méthodes de vérification de l’exigence, séparées par un « ; » -
get_requirement_verification_methods_newline- Renvoie le nom de toutes les méthodes de vérification de l’exigence, séparées par un saut de ligne -
get_requirement_verification_methods_comments- Renvoie tous les commentaires sur les méthodes de vérification de l’exigence, séparés par un double saut de ligne -
get_requirement_verification_status- Renvoie le statut de toutes les méthodes de vérification des exigences, séparé par un « ; » -
get_requirement_verification_closeout_refs- Renvoie les noms des références de clôture pour chaque méthode de vérification des exigences, séparés par un « ; » -
get_requirement_attachments_references- Renvoie le nom de toutes les pièces jointes des exigences, séparés par un « ; » -
get_requirement_custom_field- Renvoie la valeur d’un champ personnalisé spécifique de l’exigence, passé en argument à la fonction
Fonctions de « formatage » du document
Les fonctions utilisées pour mettre en forme le document final sont les suivantes :
-
keep_tables_on_one_page- Met en forme le document final afin d’empêcher que le contenu des cellules de tableau ne s’étende sur différentes pages. -
remove_all_empty_headings- Met en forme le document final pour supprimer tous les titres vides -
remove_all_but_last_section- Met en forme le document final pour n’avoir qu’une seule section au lieu de plusieurs -
put_images- Remplace l’espace réservé des images par les images de chaque exigence -
clone_run_props- Fonction auxiliaire permettant de copier les propriétés d’un segment de texte vers un autre (utilisée pour copier les propriétés d’un texte mis en forme en HTML) -
put_html_text- Remplace l’espace réservé du texte de l’exigence par le texte mis en forme correspondant, tel que gras, italique, souligné, barré et listes à puces
Télécharger le dernier modèle générique, script Python ou exécutable
Generic Specification Creation Nov2023.py Generic Specification Template.docx requirements.txt
Éléments à modifier avant d’exécuter le script :
La procédure complète expliquant comment exécuter ce code, depuis la création des scripts jusqu’à la génération du document, est illustrée dans la vidéo ci-dessous (sans audio).
Line 27 - Line 30 L’utilisateur doit définir le nom d’utilisateur et le mot de passe pour que le script puisse s’exécuter. L’utilisateur peut utiliser la gestion des secrets et exécuter le script, ou saisir directement le nom d’utilisateur et le mot de passe dans le script. Cependant, le mot de passe sera visible par tous les utilisateurs du déploiement. Par conséquent, nous vous recommandons d’utiliser la « gestion des secrets ».
Line 31 Copiez le nom de la spécification et saisissez-le dans cette ligne.
Line 32 Téléversez le modèle de spécification générique dans la gestion des fichiers, copiez son « ID » et ajoutez-le dans cette ligne.
Line 33 Ajoutez l’« ID » du projet où se trouve la spécification.
Line 34 Vous pouvez donner un nom au document exporté.
Si vous avez besoin d’aide pour modifier le modèle, extraire d’autres informations afin d’alimenter vos modèles, ou pour toute question liée à cette fonctionnalité, n’hésitez pas à nous envoyer vos questions/demandes via notre page de support Altium.
 AI-localized
AI-localized